
My Retriever Was an LLM. That Was the Bug.
A couple of weeks ago I wrote about building Samvad, a pipeline that answers questions about Indian news coverage and shows its sources. I ended that post with three things I wanted to fix: rank on full article bodies instead of snippets, put my prompts under version control, and get comfortable letting the system return nothing.
I went and did all three. Then real queries started hitting the live version and broke it in ways my to-do list hadn’t predicted. By the time I was done the retrieval half of Samvad was rebuilt — and the root cause of the first problem turned out to be something I’d done on purpose months earlier.
The retriever was an LLM
In the first version, the Retriever was an agent. I gave a model a list of steps — embed the query, search, fetch the article bodies, rerank — and told it to follow them in order. It felt clean at the time. Agents were the whole design.
The problem is that “fetch the article body” isn’t a judgment call. It’s plumbing. But I’d handed it to a model that got to decide whether to bother, and most of the time it didn’t. So the rerank was running on titles and short descriptions, which is exactly the snippet problem I’d flagged at the end of the last post. The fix I’d written down — “rank on the full text” — was already sitting in the instructions. The model was just skipping that step.
So I tore the agent out and rewrote retrieval as plain code. A fixed recipe, same every run, with nothing getting a vote on which steps happen:
query
│
▼
Guard + Planner abuse check, plus: what kind of question is this,
│ and should it be split into sub-questions?
▼
hybrid candidates vector search + Postgres full-text, fused (RRF)
│
▼
fetch bodies the full article, not just the headline
│
▼
rerank on body one pass → how relevant, and which passages to keep
│
▼
relevance floor strong / weak / nothing (drop the junk)
│
▼
Analyst → Critic write the cited answer, then grade its groundingThe rule I settled on: keep the LLM where judgment earns its place — deciding whether a query is abuse, grading whether an answer is grounded, writing the prose — and make the mechanical parts mechanical. Retrieval is mechanical. Once it was code I could test it, and the body fetch happened every single time, because nothing got to opt out of it.
Two kinds of search, and a query that quietly did nothing
Searching by meaning works until someone asks about a specific name or number, where a plain word-for-word match does better. So retrieval runs both: a semantic pass over the embeddings and a lexical pass for the exact terms. The part I had to actually think about was how to combine them. The two passes hand back scores that aren’t comparable — a similarity distance and a text-match rank don’t live on the same scale — so instead of trying to normalise one into the other, I fused them with Reciprocal Rank Fusion, which discards the raw scores and merges on rank position alone. A small choice that sidesteps a whole category of score-blending headaches, and the one I reach for first now when two rankings have to meet.
The bug came from the lexical side. For a while, long wordy questions were quietly coming back with worse results than short ones — no error, no warning, just a slightly-worse answer than the same question asked in fewer words. The text query was being built to require every word to match, so a thirty-word research question asked for one article containing all thirty, and matched nothing. Because the semantic pass always returned something, the system sailed along looking perfectly healthy while half its search had gone dark.
A crash I’d have caught in minutes; a silent half-failure that still hands back a plausible answer took an evening to even notice. The fix was small — the kind of debugging that’s all diagnosis and no typing.
Bodies are messier than embeddings
Working from the full article instead of the headline sounds trivial. In practice it was the messiest part of the whole rebuild, because “the article” sits in a different place on every site, buried under layout and related-links, and every so often it’s a stub where the real story should be.
A lot of the work here was unglamorous judgment: telling a real article apart from the furniture around it, noticing when a page handed back a fragment instead of the whole thing, and refusing to let that fragment stand in for the story downstream. None of it shows up in a demo. All of it decides whether the cited answer above it is worth trusting.
Confidently saying nothing
The last post’s third regret was about letting the system return nothing. I thought I’d handled it: if retrieval found zero articles, the pipeline stopped and said so. What I hadn’t handled was the middle.
A real query came in asking about an “online meme war” between India and China. There was no such coverage in the corpus. But the search didn’t come back empty — it came back with eight vaguely topic-adjacent articles, and the system answered confidently over them, cited all eight, and said essentially nothing. A related query was worse: it got the Analyst to swallow the question’s premise, that there was a “war on X,” and write a fluent answer about an event that never happened.
Zero results I had covered. “Results, but bad ones” I hadn’t. So I added a relevance floor. After the rerank every article carries a relevance score, and an article only counts as real coverage if it clears the floor. That gives three outcomes where I used to have two: enough clear it and you get a full answer; one or two scrape through and you get an answer openly marked thin and low-confidence; nothing clears it and you get an honest “no coverage,” billed as zero.
The premise problem needed a second fix, further upstream. My Guard agent used to have one job, blocking abuse. Now — in the same model call that was already screening for abuse, so it adds no extra latency — it also reads the question before anything else runs and works out what kind of question it is and whether the corpus can even answer it. A question about social-media chatter, or a guess about the future, or a request for someone’s personal profile gets declined at the door, politely and for free, because a pile of published news articles structurally can’t answer it. And the Analyst picked up a rule I think of as premise discipline: if the question assumes something happened, treat that as a claim to check against the sources rather than a fact to build on.
Versioning the prompts, and a model that didn’t exist
The second regret was the dull one to describe and the most useful in practice. My prompts had been changing by me editing them in place, which meant I could never explain why answer quality moved. Now each prompt is a versioned module with a semver number, every model call records which prompt version produced it, and there’s a golden eval: a fixed set of hand-picked cases the whole pipeline runs against before any prompt change ships, scored and compared to a saved baseline.
It paid for itself the same week. When I added the question-classification step, some queries started routing to a heavier model for the synthesis-heavy ones. The eval went red. The “heavy” model I’d configured months earlier didn’t exist — I’d written down a model name that was never on the API. The Analyst had quietly run on the light model the entire time, so the wrong name had never actually been called until that day. A typo that sat dormant for months, and a test caught it before a user did.
From answers to a report
Somewhere in the middle of all this I stopped and looked at what I’d actually built. A grounded, cited answer to a news question is useful. It’s also, increasingly, something a decent general chatbot will hand you. That lane was filling up, and I wasn’t going to win it with a smaller corpus and no app.
So the centre of Samvad moved. The thing a general model genuinely can’t do is read across two dozen Indian outlets and tell you how one story was covered: who broke it, how the framing shifted over the days, which outlet leaned on a detail that another one left out. That needs a real multi-outlet corpus and a layer of analysis on top of it. That became the Coverage Report — a cited timeline of how a story unfolded, plus a four-way read of how the coverage drifted across outlets and over time, exported as a document you can take into your own work. It’s the piece of Samvad I’m proudest of.
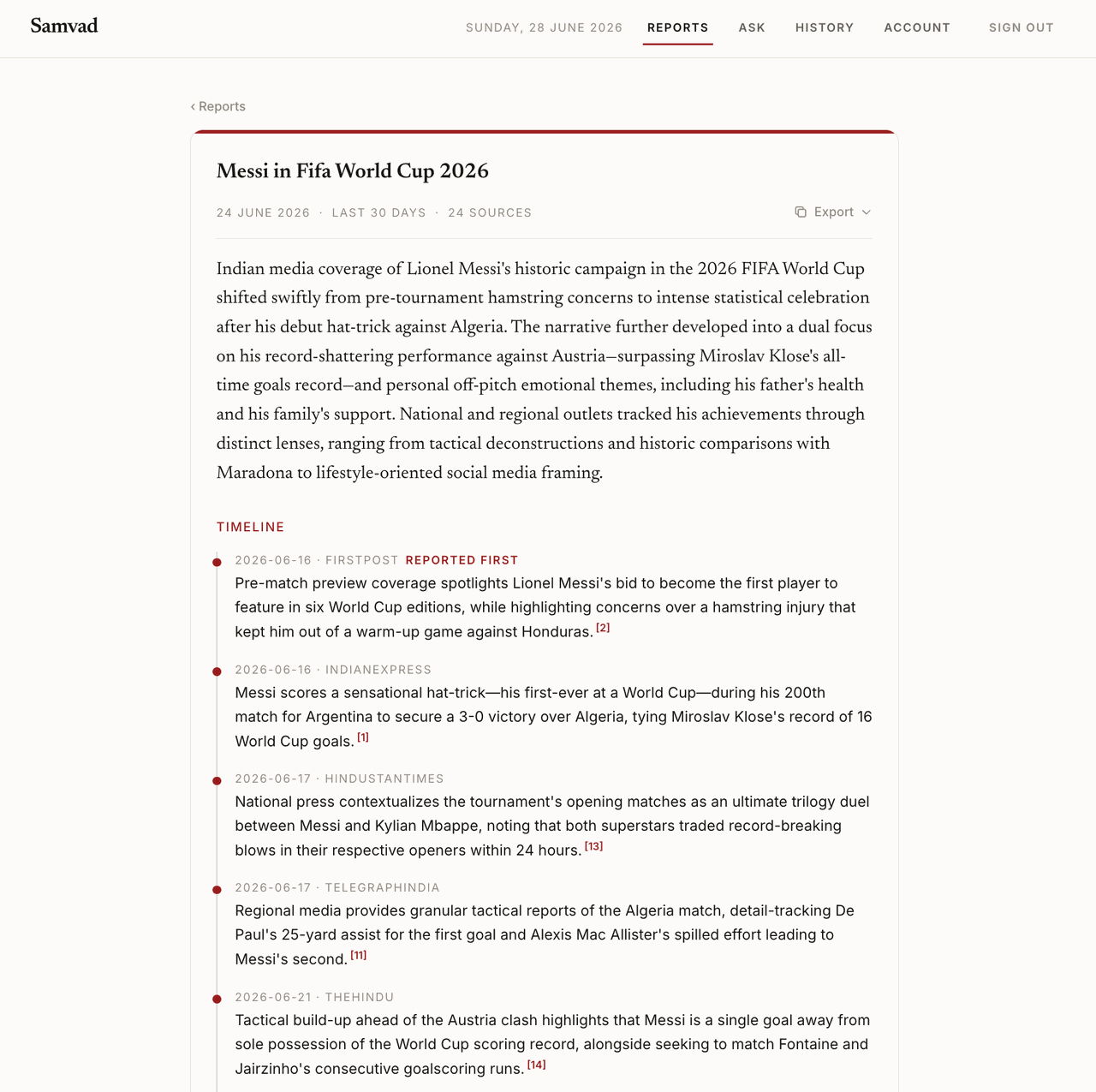
A Coverage Report in the app — a cited timeline of how India’s outlets covered one story, who got to each beat first, and a source behind every line. This one traces Messi’s 2026 World Cup run across 24 outlets.
The retrieval rebuild is what made it cheap to build. A Coverage Report wants almost the inverse of a Q&A search: instead of the dozen most relevant recent articles, it wants a wide arc of one story spread across as many outlets as possible and ordered in time, so there’s contrast worth analysing. Because retrieval was plain code by then, the second mode was mostly rearranging the same parts — same body fetch, same reranker, same relevance floor, a different selection step bolted on the end. The reports are generated in the background by a worker pulling jobs off a Postgres table, which is the queue-without-a-queue-service idea finally showing up somewhere it earns its keep.
It’s all live at ask.samvadhq.com, and new accounts start with 20 free credits — enough to run a handful of queries and a couple of Coverage Reports without paying for anything. The corpus is a couple dozen Indian outlets now, deep enough that the cross-outlet reports have something to chew on. If you try it, the part I’d point you at is the sources — open them and check whether the claim actually sits where the citation says it does. That check is the whole reason I built this, and it’s where I most want to hear when it’s wrong.